반응형
1. 문자열 SPLIT - 기본 형식
구분자로 연결된 문자열을 분리하는 경우 REGEXP_SUBSTR(문자열,'[^구분자]+'1,순번) 패턴을 사용하여 분리하는 예는 널리 알려졌다.
만일 중간에 NULL값이 포함된 경우라면? 오류가 발생한다.
/*
- 콤마(,)로 구분된 문자열
- 중간에 NULL값이 있는 경우 REGEXP_SUBSTR 함수는 엉뚱한 값을 리턴할 수 있음 (COL3, COL4)
- 정규식 [^,]+ 의 의미는 콤마가 아닌 문자열 1개 이상을 뜻함.
- 첫행의 ,, 부분은 선택되는 텍스트가 없기 때문에 잘못된 결과를 리턴한다.
*/
WITH SAMPLE_T AS (
SELECT 'A,BC,,EF' AS VAL FROM DUAL UNION ALL
SELECT 'A,BC,D,EF' AS VAL FROM DUAL
)
SELECT A.VAL
,REGEXP_SUBSTR(A.VAL,'[^,]+',1,1) AS COL1
,REGEXP_SUBSTR(A.VAL,'[^,]+',1,2) AS COL2
,REGEXP_SUBSTR(A.VAL,'[^,]+',1,3) AS COL3
,REGEXP_SUBSTR(A.VAL,'[^,]+',1,4) AS COL4
FROM SAMPLE_T A;
2. 문자열에 NULL이 포함된 경우 처리 방안 1)
- REPLACE와 TRIM 활용
/*
- 오류 해결방안(1)
- ,,를 공백을 추가하도록 치환 후 trim으로 공백 제거
*/
WITH SAMPLE_T AS (
SELECT 'A,BC,,EF' AS VAL FROM DUAL UNION ALL
SELECT 'A,BC,D,EF' AS VAL FROM DUAL
)
SELECT A.VAL
,TRIM(REGEXP_SUBSTR(REPLACE(A.VAL,',',', '),'[^,]+',1,1)) AS COL1
,TRIM(REGEXP_SUBSTR(REPLACE(A.VAL,',',', '),'[^,]+',1,2)) AS COL2
,TRIM(REGEXP_SUBSTR(REPLACE(A.VAL,',',', '),'[^,]+',1,3)) AS COL3
,TRIM(REGEXP_SUBSTR(REPLACE(A.VAL,',',', '),'[^,]+',1,4)) AS COL4
FROM SAMPLE_T A3. 문자열에 NULL이 포함된 경우 처리 방안 2)
- 정규식 패턴 활용
WITH SAMPLE_T AS (
SELECT 'A,BC,,EF' AS VAL FROM DUAL UNION ALL
SELECT 'A,BC,D,EF' AS VAL FROM DUAL
)
SELECT A.VAL
,REGEXP_SUBSTR(A.VAL,'[^,]',1,1) AS COL1
,REGEXP_SUBSTR(A.VAL,'[^,]+',1,2) AS COL2
,REGEXP_SUBSTR(A.VAL,'(.*?)(,|$)',1,3,null,1) AS COL3
,REGEXP_SUBSTR(A.VAL,'(.*?)(,|$)',1,4,null,1) AS COL4
FROM SAMPLE_T A;4. 문자열로 ROW Generation
- 뻥튀기 기법(row generation 기법, connect by 혹은 copy_t 이용)
/*
- 문자열을 기준으로 ROW Generation
- CONNECT BY를 이용하여, 구분자 만큼 루프롤 돌면서 문자열 분리함.
- 패턴의 개수는 REGEXP_COUNT 함수를 이용하여 계산
- 행마다 추출한 문자의 수가 다르므로 루프의 개수가 각 행 문자열에 따라 달라짐.<서브쿼리>
*/
WITH SAMPLE_T AS (
SELECT 'A,BC' AS VAL FROM DUAL UNION ALL
SELECT 'D,E,F' AS VAL FROM DUAL
)
SELECT A.VAL
,REGEXP_SUBSTR(A.VAL,'[^,]+',1, B.LNO) AS COL1
FROM (SELECT VAL, REGEXP_COUNT(VAL,'[^,]+') AS STR_COUNT
FROM SAMPLE_T) A
,(SELECT LEVEL LNO
FROM DUAL
CONNECT BY LEVEL <= 10 /* REGEXP_COUNT 값의 최대값을 주면 되나, 큰 값을 주면 됨. */
) B
WHERE A.STR_COUNT >= B.LNO
;5. 문자열로 ROW Generation (Lateral 활용)
/*
- 문자열을 기준으로 ROW Generation
- LATERAL 함수를 사용하면 SQL이 더 간단함
- Oracle 19c 특정 버전의 경우 LATERAL 버그가 있어 대용량 데이터에서 성능 지연 발생 가능성 존재함.
*/
WITH SAMPLE_T AS (
SELECT 1 AS NO, 'A,BC' AS VAL FROM DUAL UNION ALL
SELECT 2 AS NO, 'D,E,F' AS VAL FROM DUAL
)
SELECT A.VAL
,REGEXP_SUBSTR(A.VAL,'[^,]+',1, LNO) AS COL1
FROM SAMPLE_T A
,LATERAL(SELECT LEVEL LNO
FROM DUAL
CONNECT BY LEVEL <= REGEXP_COUNT(A.VAL,'[^,]+'))
;6. 정규식이 아닌 Substr, Instr함수를 사용하여 문자열 분리
- 정규식보다 성능에 유리
/*
- 정규식은 상당히 비싼 Operation임.
- 처리할 레코드가 많으면 function call 부하로 성능 저하의 원인이 될 수 있음
- instr과 substr함수를 사용하는 것이 성능에 더 좋음
- 연산을 간단하게 하기 위해 문자열 앞쪽에 콤마(,)를 연결 후 처리.
- 여러 레코드 처리를 하려면 LATERAL을 사용하여 구분자 개수만큼 뻥튀기 처리하면 됨.
*/
WITH SAMPLE_T AS (
SELECT ','||'A,BC,,EF'||',' AS VAL FROM DUAL
)
SELECT A.VAL, LEVEL LNO
,SUBSTR(A.VAL,INSTR(VAL,',',1,LEVEL)+1, INSTR(VAL,',',1,LEVEL+1)-INSTR(VAL,',',1,LEVEL)-1) AS COL1
FROM SAMPLE_T A
CONNECT BY LEVEL <= 4
;7. SUBSTR, INSTR를 사용하여 ROW GENERATION (LATERAL)
- 성능에 유리
/*
- 여러 레코드를 SUBSTR, INSTR함수를 사용하여 분리
- LATERAL 함수를 사용
- 추츨할 문자수는 LENGTH(문자열) - LENGTH(REPLACE(문자열,구분자)) +1 을 사용하여 계산
- 예제는 앞뒤로 구분자를 CONCAT하였으므로 -2를 추가로 함. (최종 -1)
*/
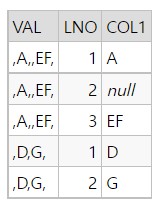
WITH SAMPLE_T AS (
SELECT ','||'A,,EF'||',' AS VAL FROM DUAL UNION ALL
SELECT ','||'D,G'||',' AS VAL FROM DUAL
)
SELECT A.VAL, LNO,
SUBSTR(VAL,INSTR(VAL,',',1,LNO)+1, INSTR(VAL,',',1,LNO+1)-INSTR(VAL,',',1,LNO)-1) AS COL1
FROM SAMPLE_T A
,LATERAL(SELECT LEVEL LNO
FROM DUAL
CONNECT BY LEVEL <= (LENGTH(A.VAL)-LENGTH(REPLACE(A.VAL,','))-1)
)
;
** 위에서 사용한 전체 SQL문 및 테스트 결과는 DB<l>FIDDLE( https://dbfiddle.uk/qAAHT-CC) 에서 확인 가능함
반응형
'SQL > SQL Tech' 카테고리의 다른 글
| DB2 Script - Schema Size (0) | 2023.06.05 |
|---|---|
| DB2 Scripts - Table Count By Schema (0) | 2023.06.05 |
| values 절 (db2, postgresql) (0) | 2022.10.21 |
| SQL Fiddle Online SQL Test Tool 비교 (0) | 2022.10.21 |
| SQL & PL/SQL Naming Convention (5) | 2010.08.06 |