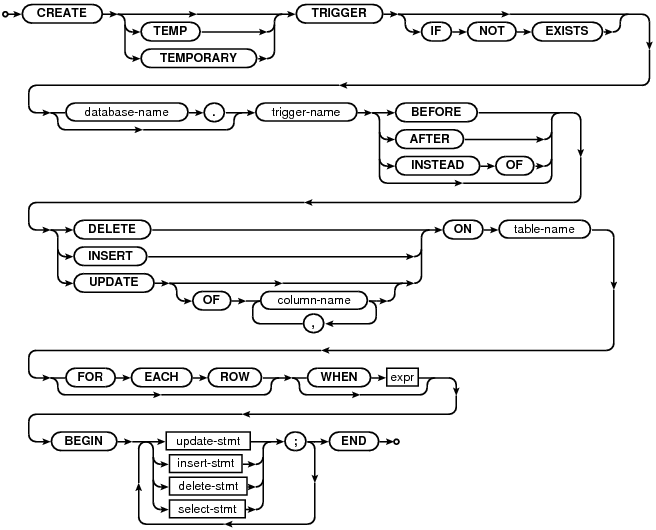
SQLite Databae에 대한 일곱번째 포스트입니다. 이번 포스트에서는 SQLite의 Trigger에 대해서 다뤄보도록 하겠습니다. SQLite User Guide 포스트 목차 1. SQLite User Guide - 소개. GUI Tools 등 2. SQLite User Guide - PRAGMA, 시스템 카탈로그, DATA TYPE 3. SQLite User Guide - DDL(CREATE, DROP 등) 4. SQLite User Guide - DML (SELECT, INSERT, UPDATE, DELETE 등) 5. SQLite User Guide - Function (내장함수, Aggregation 함수) 6. SQLite User Guide - DateTime 함수, DateTime Fo..